AWS: Such auspices are very hard to read
-
 Craig Koorn
Craig Koorn - 4 Dec 2019
Craig Koorn If you’ve ever looked into AWS security, you’ll know that getting it right is far from easy. If you don’t believe me, just search for anything along the lines of “S3 leaks” and look at the hits you get for recent weeks, months, or years – this is hardly a new problem. Why?
The short answer is that getting the fundamentals right in AWS is hard. By fundamentals I don’t mean the deploying the latest and greatest elastic-something-or-other – I mean allowing only the actions we intend, and denying everything else, everywhere. From boring old EC2 instances and S3 buckets to ultramodern SaaS solutions. I’m talking about managing access effectively, the principle of least privilege to our security purists. Simple in theory, difficult in practice – especially in AWS, where configuration is everything.
For those of you who would rather just get your hands dirty, the TL;DR of this post is that it marks the release of awspx: an initial proof-of-concept to visualize resource relationships and effective access within AWS environments (click the image below to try it out yourself).

For those of you willing to stick it out (or who’ve come back) I’ll be talking about the rationale behind this tool: the problem as I have come to understand it and why we have approached this problem in this way.
In AWS, access management means policies. Whether you’re attaching policies prepared by AWS or writing them yourself, they boil down to the same two things: actions and resources.
An action is something a principal (user, account, etc) is permitted to do – change a password, terminate an EC2 instance, read an object from an S3 bucket, etc. A resource is something those actions apply to – a user, EC2 instance, S3 bucket, object in an S3 bucket, etc…
By default, unless a policy states otherwise, all attempts to perform an action will be denied.
By using policies, we can define exactly what action(s) can be performed on what resource(s). For more flexibility, policy definitions support wild-cards, which will be resolved by AWS.
We can rely on policy definitions to behave implicitly, in which case the result is the intersection of what the defined action and resource pairs apply to. For example, if we write a policy that allows the action s3:GetObject (basically S3’s version of download), on all resources (*). This means we are implicitly restricting resources to only S3 objects (even though * really means all resources), since it wouldn’t make a whole lot of sense to perform s3:GetObject on, say, an EC2 instance.
Each pair of actions and resources form part of a policy’s statement, of which you may have one or you could have many. To give you an example, here’s a policy with one statement:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
This is actually the built-in policy AdministratorAccess. As the name would suggest, it allows all actions on all resources in your account. Seems straightforward, so what’s the issue? Well, what exactly does “all actions” mean? It depends on when you ask – AWS adds support for new services and actions all the time. As these actions change, so too will the meaning of this policy. Unless you are very familiar with every action in existence, you can’t know what it is you are granting.
Similarly, “all resources” will mean something different for everybody. Since I have yet to find an easy way to retrieve a consolidated list of resources myself, finding a definitive answer to this question becomes even tougher (ever tried to work out what’s responsible for that small but irritating AWS cost before?).
In this example, not knowing exactly what you’re granting is hardly the worst thing, and you wouldn’t want to explicitly list all 5985+ actions. We all have a pretty good idea of what AdministratorAccess means and this policy fits the definition. Where uncertainty is a real problem is in every other case, where you want to restrict access in some way. Uncertainty here means an increased likelihood of undermining the rationale behind this restriction. Couple this with a poor understanding of where AWS takes responsibility for security and where the onus is on you and things are bound to go wrong at some point.
Whether you’ve been using AWS for a while, or have only just started, one of the unrelenting challenges you will face is figuring out what actions you need to grant to make something work. We want to ensure that the thing works, while also ensuring we haven’t granted unintended access in the process.
One way to ensure that this does not happen is to meticulously vet every action and resource before cherry-picking the specific ones we require to write an explicit policy. This approach, however, turns into an incredibly time-consuming exercise of tweaking and retweaking policies and seeing what breaks. For large and complex environments, this is infeasible.
Understandably, many organizations take the following approach instead: first make sure everything works operationally, then try to spot any obvious risks introduced. This approach is far less demanding, and probably a lot more sensible, but may fail to pick up more subtle risks. It’s also highly dependent on an organization’s competency in this area. Since AWS is relatively new, many organizations do not yet have this capability.
Like every other security consultancy or function that operates in this space, the sheer insanity that is AWS access management affects us: not only do we need to identify risks within these environments, but we need to do so with little to no context. Fortunately, dealing with access management in complex environments is not a new problem.
One particularly effective approach for dealing with complex environments is to start at the end and work backwards. Start by identifying a critical asset and then look at the ways that asset could be compromised. This approach simplifies matters greatly, as we do not need to consider the environment in its entirety, but can focus on what is immediately relevant to us and gradually build up the bigger picture, piece by piece. Not only does this facilitate understanding but it also enables us to prioritize the most severe threats first. This approach is exemplified in the Active Directory space by SpectreOps’s BloodHound.
But in AWS, you can’t start from the end without starting from the beginning since there isn’t really an AWS Bloodhound equivalent. To determine what affects your critical asset, you would need to inspect every policy in the environment manually, which brings us back to where we started. What we wanted was something that would process and resolve actions and other relationships for us, consider these actions holistically to identify potential attack paths, and present this information so that it could be queried and explored visually.
Suppose we knew exactly what our critical asset was. We’re looking for ways it could be compromised. What exactly does “compromise” mean? This would depend on what our critical asset is. If the asset is a user account, compromise could be resetting the user’s login password or provisioning an access key for them. Both actions would effectively grant the same the access afforded to that user, and thus represent a compromise.
But what if we’re talking about something like an S3 bucket?
Now the purpose of the bucket starts to matter: if it stores personally identifiable information, intellectual property, or grandma’s secret recipe, then read access would represent compromise; if it’s a public website, read access is by design, and write access would be the compromise condition, as it would enable defacement. We can’t define compromise generically for all cases, so we can’t design a fully automated solution that pulls in cloud information and spits out paths to compromise.
What we can automate is the process of resolving policies, which amounts to resolving actions and resources. In so doing, we can design something that will at least support us in identifying, refining, and answering questions around access control. This isn’t too hard if you have a list of actions to match action definitions against, since they can be defined implicitly or partially.
Unlike resources, actions are not unique to each environment. In the awspx project’s earlier days, we relied heavily on cloudonaut, which detailed AWS actions for each service in more detail than I could find anywhere else. Since then, AWS documentation has improved to the point where it is now easy to directly parse and extract programmatically, at least in this specific case.
Constructing a list of resources, however, is far harder. To this day, the closest thing I have found to a central location for collated resource information is the AWS tag editor; however, there are a number of shortcomings in this approach that I will not get into here.
The approach we took was to use AWS’s official Python libary, boto3, to query the resources of services we were interested in. This meant writing custom code to ingest individual resources from individual services. Fortunately, a peer realized that we could genericise much of this process by leveraging boto3’s Resource interface, which gave us a lot of extra mileage in cases where services are supported by this interface.
Once we had both actions and resources, it was relatively straightforward to resolve policies. We ran the code against a simplistic AWS lab environment and dropped the results into graph database (Neo4j specifically) and visually, this was the outcome:
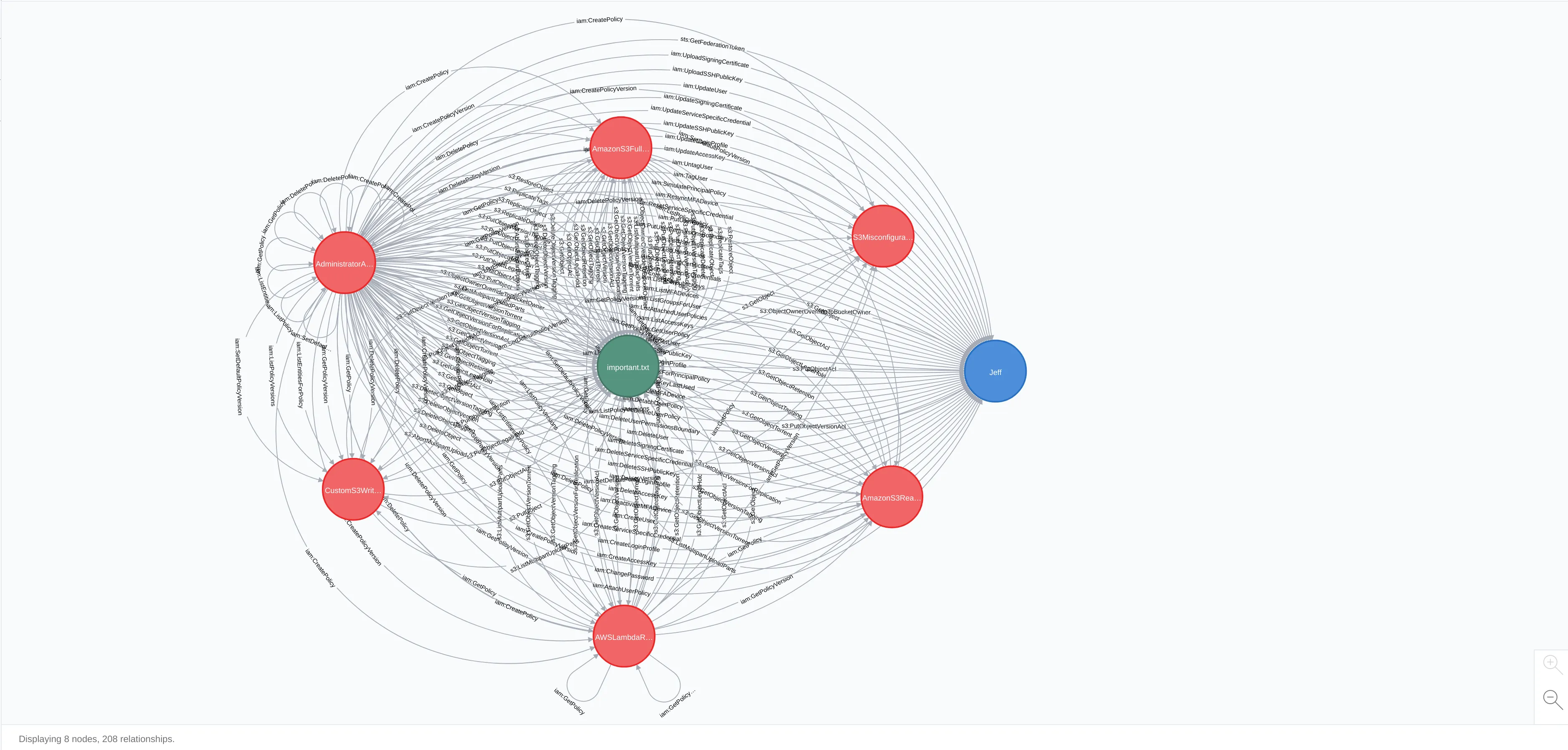
I think the big takeaway here is that there is a lot going on: many of the nodes in this graph affect one another, illustrating just how tightly coupled, interlinked, and complex access actually is in AWS. Unsurprisingly, there is a lot you can do with AdministratorAccess, which affects all 8 of nodes in this graph (including itself).
As discussed previously, actions that constitute compromise, for some given resource, are highly dependent on the nature of that resource. However, admin can perform all actions on all resources, which means that any path to admin is also a path to the action(s) representing compromise. This means that identifying paths to admin is always relevant irrespective of an environment’s context. While we can cannot compute paths to compromise, without defining what compromise means first, we can compute paths to admin since it implies compromise in all contexts.
All examples of policies I have given are officially known as identity-based policies. These belong exclusively to the Identity and Access Management (IAM) service. Identity-based policies can be stand-alone managed policies, or they can be specified inline in a user, group or role.
A managed policy differs from an inline policy in that it can be attached to multiple users, groups or roles. The relationship between a managed policy and its attached entities is one of transitivity: since the managed policy can perform a particular set of actions, so too can each attached entity.
How actions are applied may just seem like a matter of preference but it is something we need to understand if we are to even attempt mapping out actions and potential attack paths within an environment.
The greatest challenge I faced during the course of this project was trying to wrap my head around how to approach the identification of attacks. At first, the problem appears simple. Certain actions imply transitivity, for example, iam:UpdateLoginProfile, which could be used to reset a user’s console password. All we would need to do is perform a graph-based search for these actions, then draw new edges from the entities that could transitively perform them, to the resources affected by those actions.
The first step was not too bad, but the steps after that get real hard, real quick.
To give you a practical example, suppose we had a user with only the following managed policy attached:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PutGroupPolicy",
"Resource": "*"
}
]
}
This policy would allow this user to write an arbitrary inline policy to any group. If this user is in a group, this policy effectively makes them admin, as they can write an inline policy granting admin access to the group they’re in. But if they’re not in a group, they can’t do this.
Now suppose we also attached this policy to the user:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:AddUserToGroup",
"Resource": "*"
}
]
}
If any group exists, the attack still applies. If no groups exist, then neither does the attack. If we extended the actions this user had to include iam:CreateGroup, then they would be able to reach admin in either of these two cases.
Suppose we attached these same two policies to a role. Would this role be admin? Since it’s not a user, it cannot add itself to a group and so the remainder of the path is no longer viable. What if we created another role, attached these same policies but also added iam:UpdateLoginProfile: this role could then reset a user’s console password and make that user Admin. What if we delete this user?
We can go on doing this for a very long time.
To establish the precise combination of actions producing a new edge for all cases becomes very difficult. What we’re considering here is the outcome, which may include a series of steps, or other attacks.
If we think of the problem in this way, what we are really trying to determine is the set of actions that together imply transitivity and produce a new edge AND whether those actions have a dependency. Then, in the case of the first example, the set of actions becomes PutGroupPolicy with the dependency Group. How exactly we get to a Group is defined by what other attacks, or transitive relationships, exist (for which we may have many options).
One dependency that will often decide the viability of an attack will be whether the dependency can be satisfied by creating it. This means we must also define attack patterns that describe this activity. This presents its own challenges since actions affect resources, and a resource must exist for this relationship to exist. If the resource already exists, it cannot be created. We must therefore make an exception for how these create actions are handled and introduce a special kind of generic resource (that doesn’t really exist but has the potential to). If we are to incorporate these generic resources into our graph we must ensure that actions that would affect them when they are created, affect them now.
Now we need to define patterns describing these creation attacks. These patterns must imply transitivity, otherwise we may introduce false positives. Consider the action iam:CreateUser. This action alone does not imply transitivity since you will not be able to reach the user after creating it. To use it, you must be permitted to perform other actions, such as iam:CreateAccessKey or iam:CreateLoginProfile (which changes user password). Thus we must create two attack patterns: one dependent on iam:CreateUser and iam:CreateAccessKey, and one dependent on iam:CreateUser and iam:CreateLoginProfile.
In some cases, actions that would give rise to an attack path do not affect the same resource to which that attack path applies. To clarify, consider the action iam:AttachGroupPolicy, which will allow you to attach a managed policy to a group. Intuitively, this action appears to affect both groups and policies, but technically it only affects groups. Why, you ask? Because the resource level permissions (the Resource field in a policy’s statement) associated with this action only allows you to specify and restrict this action to groups.
We must therefore include additional information in the pattern definition associated with this action to indicate that the resultant edge produced by its discovery grants transitivity to a policy and not to a group.
This model proved effective for identifying attack paths we had purposefully created in a lab environment by simply iterating through them; however, something that became very apparent, very quickly, is that the order matter. Since attack definitions, or patterns, both give rise to, and make use of, other attacks, the topology of the graph changes with each attack. This means we may process an attack that satisfies a dependency for a previously processed attack without knowing it. To avoid this, we opted to repeatedly search through our list of known attacks until the graph converges, i.e. until no new attacks are discovered for an entire round.
Performance is another necessary consideration. One early optimization was to exclude paths to admin as soon as they’re identified. Since admin is the superset for actions, and actions are the basis for attacks, searching further becomes redundant (all subsequent attack patterns will match). This, however, requires that we can identify admin, a challenge in itself.
If we stick too closely to the strict definition of admin, we may fail to identify a stop case for this exclusion process, an environment may not necessarily have a policy that mirrors our Admin policy exactly. A definition better suited to this case would be: anything that can modify the actions it can perform. Since we can identify the actions that facilitate this activity, all we have to do is update their definitions to include this information, much the same as we already did with grants.
When we put this all together, it works… just not well. While we have successfully managed to reduce arbitrary attack combinations into singular meta edges that incorporate this information, we end up with a lot of duplicates. Consider what would happen if we combined AddUserToGroup and PutGroupPolicy into a single policy: the corresponding attack would apply to both the policy and the user attached to it. If we create new attack edges from both resources, the attack applies to the user twice, since its relationship to this policy is transitive. What we actually want is a new edge from this policy, but not the user.
We added some pruning logic inline to handle this case, updated our pattern definitions to include associated AWS CLI commands that could be resolved to the resources they refer, threw in a web-based frontend, ran it against our lab environment, and what we ended up with looked exactly like this:
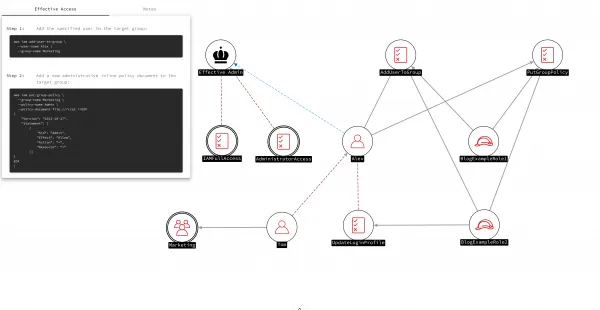
What you are looking at is a successfully identified attack path that indicates the user Alex (the user from our examples) is effectively admin. If Alex were to execute the commands illustrated on the left into the command line, she would become admin – something we think is pretty cool.
What we have is a PoC that can resolve complex policies (identity- and resource-based, or variants thereof) for supported services, including those which incorporate things we neglected to discuss like NotActions, NotResources, Conditions, and Resources incorporating variables.
What we don’t have is a comprehensive, production-ready solution that seamlessly handles extraordinarily large AWS environments or datasets (I personally guarantee it is not without issue).
What we have is a basis to work from, something that can and should be extended. Of the 175 services currently offered by AWS, so far we have only looked into IAM, EC2, S3, and Lambda (some more superficially than others).
We have the means to consider things like effective access by incorporating attack patterns describing attacks at a high level. We have not added support for all known attacks (Rhino Security Labs and CyberArk done some interesting work in this area), nor have we taken Deny actions into account – which would, in addition to reducing false positives, support a whole suite of new patterns (for example, detaching policies that enforce restrictions).
We have the ability to explore and visualize resources and actions, their properties and their relationships with other resources.
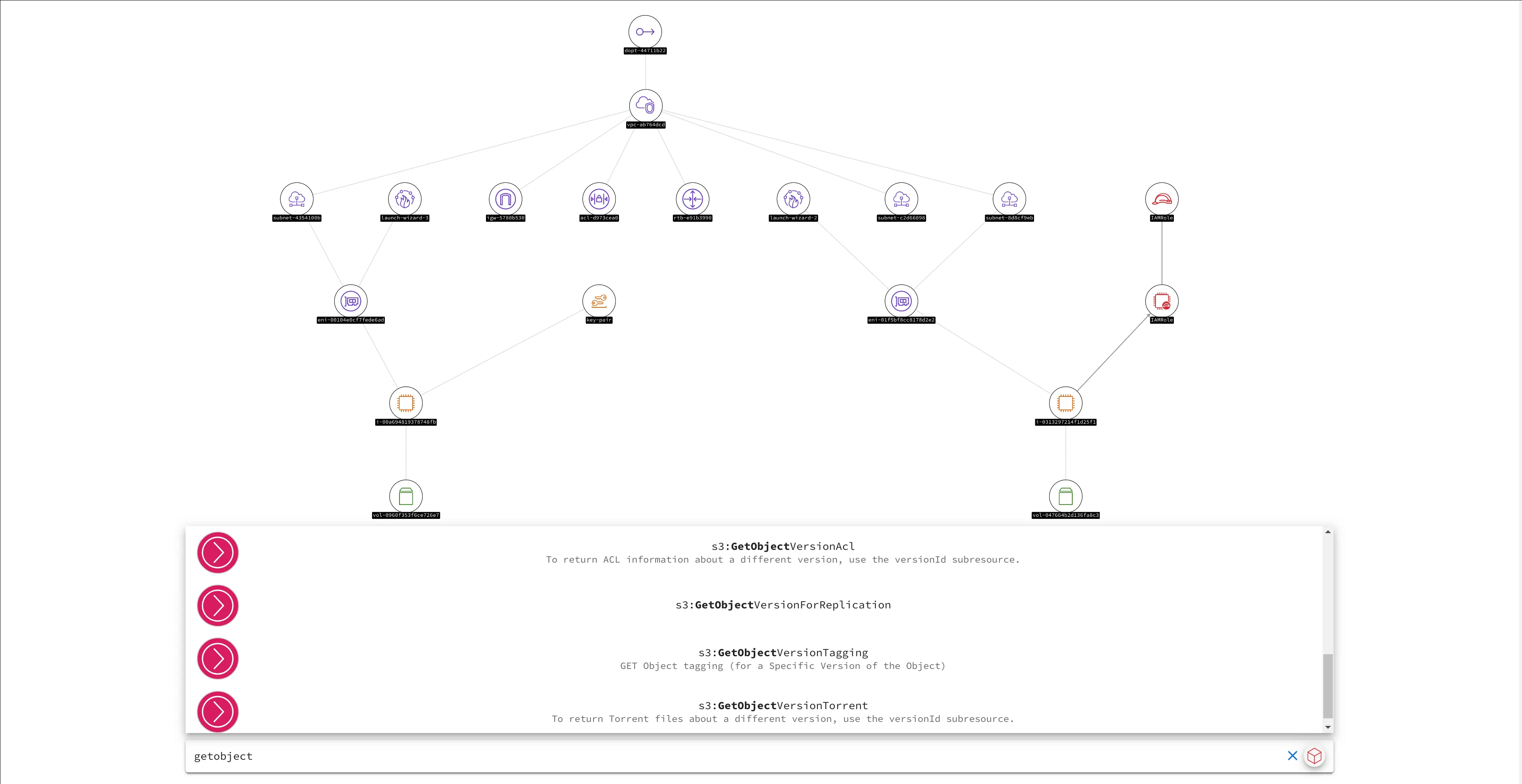
But most importantly, we now have the capability to start answering questions like “What effectively has access to this resource?” or “What can this resource effectively do?”
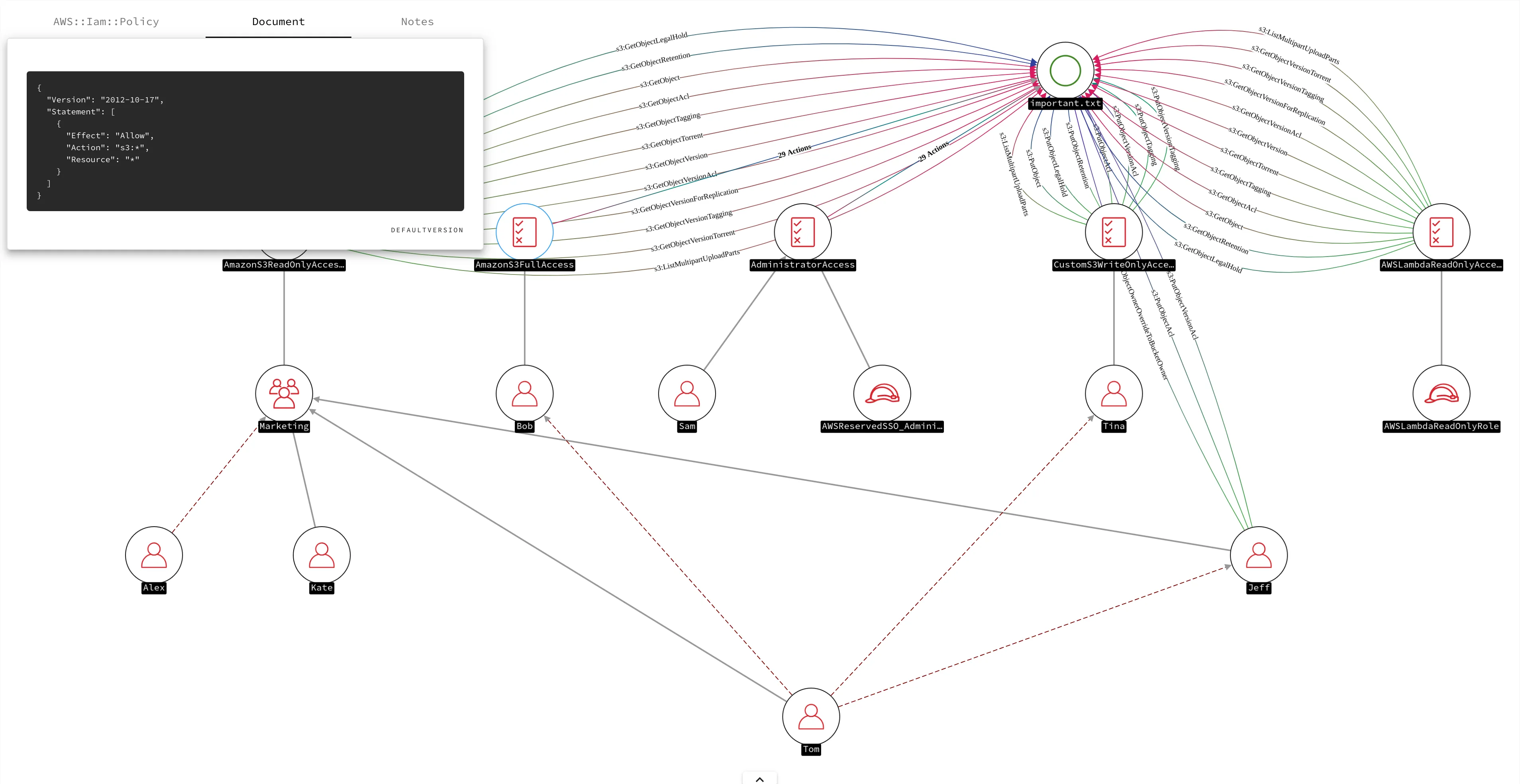
We hope you find it useful.